-
[WEEK02] 정글 5기 - 컴퓨팅 사고로의 전환정글 크래프톤 5기 회고 및 정리/WIL 2024. 3. 28. 14:35
1. 그래프 종류/표현방식
그래프 란? - 그래프는 연결할 객체를 나타내는 정점(Vertext)와 객체를 연결하는 간선(Edge)의 집합으로 구성된다.
- 그래프는 G를 G = (V, E)로 정의하는데, V는 정점의 집합, E는 간선들의 집합을 의미한다.
- 그래프에서 두 정점 Vi와 Vj가 연결되어 간선 (Vi, Vj)가 있을 때, 두 정점 Vi와 Vj를 인접(adjacent)한다 하고, 간선(Vi, Vj)는 정점 Vi와 Vj 부속(incident)되어 있다고 한다.트리 란? - 그래프 중 하나로 그래프의 특징처럼 정점과 간선으로 구성되고, 트리 구조로 배열된 일종의 계층적 데이터의 집합
- 루프 노드, 내부 노드, 리프 노드 등으로 구성된다.
- 특징
ㆍ1. 부모, 자식 계층 구조를 가진다.
ㆍ2. 간선수 = 노드수 - 1
ㆍ3. 트리 내의 노드끼리의 경로는 반드시 존재
- 트리는 Binary Tree, Binary 힙(최소힙, 최대힙), Binary Search Tree 등이 있다.
ㆍBinary Tree : 자식 노드를 2개만 가지는 Tree그래프 트리 방향성 방향 그래프 혹은 무방향 그래프 방향 그래프 순환성 순환 및 비순환 비순환 루트 노드 존재여부 루트 노드가 없음 루트 노드가 존재 노드간 관계성 부모와 자식 관계 없음 부모와 자식 관계 모델의 종류 네트워크 모델 계층 모델 그래프 관련 용어 정점
(Vertex or Node)- 데이터를 저장하는 위치 간선
(Edge)- 정점(노드)를 연결하는 선
- 링크(Link) 또는 브랜치(branch)로도 불린다.인접 정점
(adjacent vertex)- 간선에 의해 직접 연결된 정점을 의미한다. 단순 경로
(simple path)- 경로 중에서 반복되는 정점이 없는 경우를 의미한다.
- 한붓 그리기와 같이 같은 간선을 지나가지 않는 경로를 의미한다.차수
(degree)- 무방향 그래프에서 하나의 정점에 인접한 정점의 수를 의미한다 진출 차수
(in-degree)- 방향 그래프에서 외부로 향하는 간선의 수를 의미한다. 진입 차수
(out-degree)- 방향 그래프에서 외부에서 들어오는 간선의 수를 의미한다. 경로 길이
(path length)- 경로를 구성하는데 사용된 간선의 수를 의미한다. 사이클
(cycle)- 단순 경로의 시작 정점과 종료 정점이 동일한 경우를 의미한다. 가중치 - 가중치는 간선과 정점 사이에 드는 비용을 뜻한다.
- 1번 노드와 2번 노드까지 가는 비용이 한 칸이라면 1번 노드에서 2번 노드까지는의 가중치는 한 칸이다.종류 *
Undirected (무방향)
그래프- 두 정점을 연결하는 간선에 방향이 없는 그래프 
- 무방향 그래프에서 정점 Vi와 Vj를 연결하는 간선을 (Vi, Vj)로 표현하는데, 이때 (Vi, Vj)와 (Vj, Vi)는 같은 간선이다.
- V(G1) = { A, B, C, D }
E(G1) = { (A, B), (A, D), (B, C), (B, D), (C, D) }*
Directed (방향)
그래프- 방향 그래프는 간선에 방향이 있는 그래프 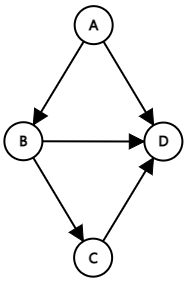
- 방향 그래프에서 정점 Vi와 Vj를 연결하는 간선 <Vi, Vj>로 표현하는데 Vi를 꼬리(tail), Vj를 머리(head)라고 합니다. 이때 <Vi, Vj>와 <Vj, Vi>는 서로 다른 간선입니다.
- V(G1) = { A, B, C, D }
E(G1) = { <A, B>, <A, D>, <B, C>, <B, D>, <C, D>}Complete (완전)
그래프- 완전 그래프는 한 정점에서 다른 모든 정점과 연결되어 최대 간선 수를 갖는 그래프 
- 정점이 n개인 완전 그래프에서 무방향 그래프의 최대 간선 수는 n(n-1)/2이고 방향 그래프의 최대 간선 수는 n(n-1)입니다.Subgraph (부분)
그래프- 부분 그래프는 기존의 그래프에서 일부 정점이나 간선을 제외하여 만든 그래프 
*
Weighted Graph- 가중 그래프는 정점을 연결하는 간선에 가중치(weight)를 할당한 그래프 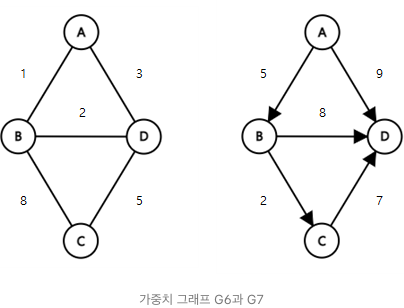
DAG
( Directed Acyclic Graph)- 유향 비순환 그래프는 방향 그래프에서 사이클이 없는 그래프 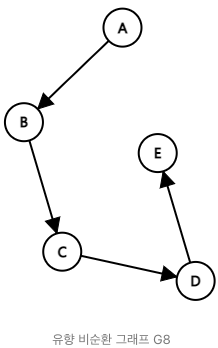
연결 그래프
(Connected Graph)- 떨어져 있는 정점이 없는 그래프 
단절 그래프
( Disconnected Graph)- 연결되지 않은 정점이 있는 그래프 
표현(구현) 방식 
[예시]인접 행렬(Adjacency Matrix) - 인접 행렬이란 그래프의 정점을 2차원 배열로 만든 것이다.
- 정점 간에 직접 연결되어 있다면 1, 아니라면 0을 저장한다.
- 장점
ㆍ2차원 배열에 모든 정점의 간선 정보가 담겨있기 때문에 두 정점에 대한 연결을
조회할 때는 O(1) 시간복잡도를 가진다.
ㆍ인접 리스트에 비해 구현이 쉽다.
- 단점
ㆍ모든 정점에 대한 간선 정보를 입력해야 하므로 인접 행렬을 생성할 때는
O(n^2)의 시간 복잡도가 소요된다.
ㆍ항상 2차원 배열이 필요하므로 필요 이상의 공간이 낭비된다.인접리스트(Adjacency List) - 인접 리스트는 그래프의 노드를 리스트로 표현한 것이다. 주로 정점의 리스트 배열을 만들어서 관계를 설정한다. 
- 장점
ㆍ정점들의 연결 정보를 탐색할 때 O(n) 시간 복잡도가 소요된다. (n은 간선의 갯수)
ㆍ필요한 만큼 공간을 사용하기 때문에 인접 행렬에 비해 상대적으로 공간의 낭비가 적다.
- 단점
ㆍ특정 두 정점이 연결되어 있는지 확인하기 위해서는 인접 행렬에 비해 시간이 오래 걸린다.
ㆍ구현이 인접 행렬에 비해 어렵다.
2. BFS/DFS
DFS
(깊이 우선 탐색)- 갈 수 있는 만큼 최대한 깊이 가고, 더 이상 갈 곳이 없다면 이전 정점으로 돌아가는 방식으로 그래프를 순회한다.
- 주로 재귀 호출과 스택을 사용해서 구현
- 모든 노드를 방문하고 싶을 때
- 시간복잡도 : O(N)DFS의
구체적인 동작 과정1. 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
2. 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접노드를 스택에 넣고 방문 처리를 한다.
ㆍ방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.# DFS 메서드 정의 def dfs(graph, v, visited): # 현재 노드를 방문 처리 visited[v] = True print(v, end=' ') # 현재 노드와 연결된 다른 노드를 재귀적으로 방문 for i in graph[v]: if not visited[i]: dfs(graph, i, visited) # 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트) graph = [ [], [2,3,8], [1,7], [1,4,5], [3,5], [3,4], [7], [2,6,8], [1,7] ] # 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트) visited = [False] * 9 # 정의된 DFS 함수 호출 dfs(graph, 1, visited) # 1 2 7 6 8 3 4 5BFS
(넓이 우선 탐색)- 쉽게 말해 가까운 노드부터 탐색하는 알고리즘
- 주로 큐와 반복문을 사용해서 구현한다.
- 두 노드 간의 최단 경로 또는 임의의 경로 탐색
- 탐색에 O(N) / 일반적으로 수행시간이 DFS보다 좋은편BFS의
구체적인 동작 과정1. 탐색 시작 노드를 큐에 삽입하고 방문 처리한다.
2. 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
3. 2번의 과정을 더 이상 수행할 수 없을 때까지 반복하다from collections import deque # BFS 메서드 정의 def bfs(graph, start, visited): # 큐(Queue) 구현을 위해 deque 라이브러리 사용 queue = deque([start]) # 현재 노드를 방문 처리 visited[start] = True # 큐가 빌 때까지 반복 while queue: # 큐에서 하나의 원소를 뽑아 출력 v = queue.popleft() print(v, end=' ') # 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입 for i in graph[v]: if not visited[i]: queue.append(i) visited[i] = True # 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트) graph = [ [], [2,3,8], [1,7], [1,4,5], [3,5], [3,4], [7], [2,6,8], [1,7] ] # 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트) visited = [False] * 9 # 정의된 BFS 함수 호출 bfs(graph, 1, visited) # 1 2 3 8 7 4 5 6정리
DFS BFS 동작원리 스택 큐 구현방법 재귀함수 이용 큐 자료구조 이용
3. 위상정렬
설명 - 위상 정렬(Topology Sort)은 정렬 알고리즘의 일종이다.
- 위상 정렬은 순서가 정해져 있는 일련의 작업을 차례대로 수행해야 할 때 사용할 수 있는 알고리즘이다.
- 조금 더 이론적으로 설명하자면, 위상 정렬이란 방향 그래프의 모든 노드를 '방향성에 거스르지 않도록 순서대로 나열하는 것' 이다.
- 그래프상에서 선후 관계가 있다면, 위상 정렬을 수행하여 모든 선후 관계를 지키는 전체 순서를 계산할 수 있다.
- 위상 정렬 알고리즘을 자세히 살펴보기 전에, 먼저 진입(indegree)를 알아야 한다.
ㆍ진입 차수란 특정한 노드로 '들어오는' 간선의 개수를 의미한다.알고리즘 1. 진입차수가 0인 노드를 큐에 넣는다.
2. 큐가 빌 때까지 다음 과정을 반복한다.
ㆍ큐에서 원소를 꺼내 해당 노드에서 출발하는 간선을 그래프에서 제거한다.
ㆍ새롭게 진입차수가 0이 된 노드를 큐에 넣는다.
- 다만, 기본적으로 위상 정렬 문제에서는 사이클이 발생하지 않는다고 명시하는 경우가 더 많으므로, 여기서는 사이클이 발생하는 경우는 고려하지 않는다.시간복잡도 - 위상 정렬의 시간 복잡도는 O(V+E)이다.
- 위상 정렬을 수행할 때는 차례대로 모든 노드를 확인하면서, 해당 노드에서 출발하는 간선을 차례대로 제거해야 한다.
- 결과적으로 노드와 간선을 모두 확인한다는 측면에서 O(V+E)의 시간이 소요되는 것이다.특징 - 위상 정렬은 DAG에 대해서만 수행할 수 있다.
ㆍDAG(Direct Acyclic Graph) : 순환하지 않는 방향 그래프
- 위상 정렬에는 여러 가지 답이 존재할 수 있다.
ㆍ한 단계에서 큐에 새롭게 들어가는 원소가 2개 이상인 경우가 있다면 여러 가지 답이 존재한다.
-모든 원소를 방문하기 전에 큐가 빈다면 사이클이 존재한다고 판단할 수 있다.
ㆍ사이클에 포함된 원소 중에서 어떠한 원소도 큐에 들어가지 못한다.
- 스택을 활용한 DFS를 이용해 위상 정렬을 수행할 수도 있다.Code 예시)
from collections import deque # 노드의 개수와 간선의 개수를 입력받기 v, e = map(int, input().split()) # 모든 노드에 대한 진입 차수는 0으로 초기화 indegree = [0] * (v + 1) # 각 노드에 연결된 간선 정보를 담기 위한 연결 리스트(그래프) 초기화 graph = [[] for i in range(v + 1)] # 방향 그래프의 모든 간선 정보를 입력받기 for _ in range(e): a, b = map(int, input().split()) graph[a].append(b) # 정점 A에서 B로 이동 가능 # 진입차수를 1 증가 indegree[b] += 1 # 위상 정렬 함수 def topology_sort(): result = [] # 알고리즘 수행 결과를 담을 리스트 q = deque() # 큐 기능을 위한 deque 라이브러리 사용 # 처음 시작할 때는 진입차수가 0인 노드를 큐에 삽입 for i in range(1, v + 1): if indegree[i] == 0: q.append(i) # 큐가 빌 때까지 반복 while q: # 큐에서 원소 꺼내기 now = q.popleft() result.append(now) # 해당 원소와 연결된 노드들의 진입차수에서 1 빼기 for i in graph[now]: indegree[i] -= 1 # 새롭게 진입차수가 0이 되는 노드를 큐에 삽입 if indegree[i] == 0 q.append(i) # 위상 정렬을 수행한 결과 출력 for i in result: print(i, end=' ') topology_sort() # 입력 예시 7 8 1 2 1 5 2 3 2 6 3 4 4 7 5 6 6 4 # 출력 예시 1 2 5 3 6 4 7
4. B-Tree
B-트리 란? - 데이터베이스와 파일 시스템에서 널리 사용되는 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다. 특징 - B트리는 이진트리와 다르게 하나의 노드에 많은 수의 정보를 가지고 있을 수 있다.
- 최대 M개의 자식을 가질 수 있는 B트리를 M차 B트리라고 하며 다음과 같은 특징이 있다.
ㆍ노드는 최대 M개부터 M/2개 까지의 자식을 가질 수 있다.
ㆍ노드에는 최대 M - 1개 부터 [M/2] - 1개의 키가 포함될 수 있다.
ㆍ노드의 키가 x개라면 자식의 수는 x + 1개 이다.
ㆍ최소차수는 자식수의 하한값을 의미하며, 최소차수가 t라면 M = 2t - 1을 만족한다.
( 최소차수 t가 2라면 3차 B트리이며, key의 하한은 1개이다. )
- 다음은 차수가 3인 B트리이다.
ㆍ파란색 부분은 각 노드의 key를 나타내며,
ㆍ빨간색 부분은 자식 노드들을 가르키는 포인터이다.
ㆍkey들은 노드 안에서 항상 정렬된 값을 가지며,
이진검색 트리처럼 각 key들의 왼쪽자식들은 항상 key보다 작은 값을, 오른쪽은 큰 값을 가진다.검색 과정 - 루트노드에서 시작해서 하향식으로 검색을 수행한다.
- 검색하고자 하는 key를 k라고 했을 때 검색과정이다.
ㆍ1. 루트 노드에서 시작하여 key들을 순회하면서 검사한다.
ㆍ1-1. 만일 k와 같은 key를 찾았다면 검색을 종료한다.
ㆍ1-2. 검색하는 값과 key들의 대소관계를 비교한다.
어떤 key들 사이에 k가 들어간다면 해당 key들 사이의 자식노드로 내려간다.
ㆍ2. 해당 과정을 리프노드에 도달할 때까지 반복한다. 만일 리프코드에도 k와 같은 key가 없다면 검색 실패삽입 과정 - key를 삽입하기 위해서는
ㆍ1. 요소 삽입에 적절한 리프 노드를 검색하고,
ㆍ2. 필요한 경우 노드를 분할해야한다.
- 리프노드 검색은 하향식이지만 노드 분할의 과정은 상향식으로 이루어진다.
- 삽입하고자 하는 값을 k로 하였을 때 삽입 과정이다.
ㆍ1. 트리가 비어있으면 루트 노드를 할당하고 k를 삽입한다.
만일 루트노드가 가득 찼다면, 노드를 분할하고 리프노드가 생성된다.
ㆍ2. 이후부터 삽입하기에 적절한 리프노드를 찾아 k를 삽입한다.
삽입위치는 노드의 key값과 k값을 검색 연산과 동일한 방법으로 비교하면서 찾는다.
* Case01 - 분할이 일어나지 않는 겨우
- 리프노드가 가득차지 않았다면, 오름차순으로 k를 삽입
* Case02 - 분할이 일어나는 경우
- 만일 리프노드에 key노드가 가득 찬 경우, 노드를 분할해야 한다.
ㆍ1. 오름차순으로 요소를 삽입한다. 노드가 담을 수 있는 최대 key 개수를 초과하게 된다.
ㆍ2. 중앙값에서 분할을 수행한다. 중앙값은 부모 노드로 병합하거나 새로 생성된다.
왼쪽 키들은 왼쪽 자식으로, 오른쪽 키들은 오른쪽 자식으로 분할된다.
ㆍ3. 부모 노드를 검사해서 또 다시 가득 찼다면, 다시 부모노드에서 위 과정을 반복한다.삭제 과정 - 요소를 삭제하기 위해선
ㆍ1. 삭제할 키가 있는 노드 검색
ㆍ2. 키 삭제
ㆍ3. 필요한 경우, 트리 균형 조정
- 용어 정리
ㆍinorder predecessor : 노드의 왼쪽 자손에서 가장 큰 key
ㆍinorder successor : 노드의 오른쪽 자손에서 가장 작은 key
ㆍ부모key : 부모노드의 key들 중 왼쪽 자식으로 본인 노드를 가지고 있는 key값이다.
단, 마지막 자식노드의 경우에는 부모의 마지막 key이다.삭제 과정
(자세히)1. 삭제할 key kkk가 리프에 있는 경우 1.1) 현재 노드의 key 개수가 최소 key 개수보다 크다면
ㆍ다른 노드들에 영향 없이 해당 k를 단순 삭제한다.
1.2) 왼쪽 또는 오른쪽 형제 노드의 key가 최소 key 개수 이상이라면
ㆍ1. 부모 key 값으로 k를 대체한다.
ㆍ2. 최소키 개수 이상의 키를 가진 형제 노드가
왼쪽 형제라면 가장 큰 값을,
오른쪽 형제라면 가장 작은 값을 부모key로 대체
1.3) 왼쪽, 오른쪽 형제 노드의 key가 최소 key 개수이고,
부모노드의 key가 최소개수 이상이면
ㆍ1. k를 삭제한 후, 부모key를 형제 노드와 병합
ㆍ2. 부모노드의 key 개수를 하나 줄이고,
자식 수 역시 하나 줄여 B-Tree를 유지한다.
1.4) 자신과 형제, 부모 노드의 key 개수가 모두 최소 key 개수라면
ㆍ부모노드를 루트노드로 한 부분 트리의 높이가 줄어드는
경우이기 때문에 재구조화의 과정이 일어난다.2. 삭제할 key kkk가 내부 노드에 있고,
노드나 자식에 키가 최소 키수보다 많을 경우1. 현재 노드의 inorder predecessor 또는 inorder successor와 k의 자리를 바꿉니다.
2. 리프노드의 k를 삭제하게 되면, 리프노드가 삭제되었을 때의 조건으로 변한다. 삭제한 리프노드에 대해서 Case 1 조건으로 이동3. 삭제할 key kkk가 내부 노드에 있고,
노드에 key 개수가 최소 key 개수만큼,
노드의 자식 key 개수도 모두 최소 key 개수인 경우- 삭제할 key k가 있는 노드도 최소, 자식노드들도 최소의 key 개수를 가지므로, k를 삭제하면 트리의 높이가 줄어들어 재구조화가 일어나는 케이스이다.
- 재구조화 과정
ㆍ1. k를 삭제하고, k의 양쪽 자식을 병합하여 하나의 노드로 만든다.
ㆍ2. k의 부모key를 인접한 형제 노드에 붙인다.
이후, 이전에 병합했던 노드를 자식노드로 설정한다.
ㆍ3. 해당 과정을 수행하였을 때 부모노드의 개수에 따라
수행과정이 다르다.
ㆍ3-1. 만일 새로 구성된 인접 형제노드의 key가 최대 key 개수를 넘어갔다면, 삽입 연산의 노드 분할 과정을 수행한다.
ㆍ3-2. 만일 인접 형제노드가 새로 구성되더라도 원래 k의 부모 노드가 최소 key의 개수보다 작아진다면, 부모 노드에 대하여 2번 과정부터 다시 수행한다.(추가) 삭제 과정 요약 1. 삭제하는 왼쪽 노드의 가장 오른쪽값과 변경 후 삭제
2. 형제노드가 있을 시 부모로 올리고 정렬 후 다시 내린다.
3. 형제노드가 없다면 부모를 내리고 형제와 병합** 동작 과정들이 이해가 되지 않는다면 해당 블로그를 참고 부탁드립니다. **
번외 - B-tree와 B+-tree 의 차이점
B-tree B+tree 리프 노드 구조 - 데이터를 저장하는 역할
- 각 리프 노드는 키와 해당 키에 대응하는 데이터의 포인터를 가지고 있다.- 데이터를 저장하는 역할을 하지만, 리프 노드간에 연결 리스트로 구성
- 이런 구조는 범위 검색과 순차 액세스를 효율적으로 수행인덱스 노드 구조 - 인덱스 노드는 키와 해당 키에 대응하는 자식 노드의 포인터를 가지고 있다. - 인덱스 노드는 키와 해당 키 이상의 범위에 속하는 데이터의 포인터를 가지고 있다.
- 이런 구조는 범위 검색을 효율적으로 수행데이터 저장 방식 - 인덱스 노드와 리프 노드 모두에 키와 데이터의 포인터가 저장 - 인덱스 노드에는 키만 저장되고, 리프 노드에는 키와 데이터의 포인터가 저장
- 이런 구조는 리프 노드의 크기를 키 값만큼 더 크게 가져가도록 하여 데이터의 분포를 효율적으로 관리범위 검색의 성능 - 범위 검색을 상대적으로 느릴 수 있다.
- 키의 위치를 찾은 후에 리프 노드까지 내려가야 하기 떄문- 리프 노드 간의 연결 리스트를 통해 범위 검색이 효율적으로 수행
- 범위 검색에 더 적합한 구조를 가지고 있다.
5. 트라이(Trie)
트라이 란? 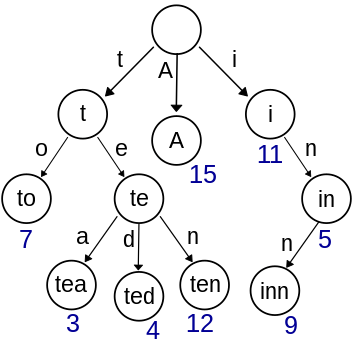
- 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조
- 우리가 검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어 있는 자료구조
- 래딕스 트리(radix tree) or 접두사 트리(prefix tree) or 탐색 트리(retrieval tree)라고도 한다.
ㆍ트라이는 retrieval tree에서 나온 단어이다.
- 예를 들어 'Datastructure'라는 단어를 검색하기 위해서는 제일 먼저 'D'를 찾고, 다음에 'a', 't' ... 의 순서로 찾으면 된다. 이러한 개념을 적용한 것이 트라이 이다.목적 & 장단점 - 사용하는 이유는 문자열의 탐색을 하고자할 때 시간복잡도를 보면 알 수 있다.
ㆍ단순하게 하나씩 비교하면서 탐색을 하는 것보다 훨씬 효율적이다.
ㆍ단, 빠르게 탐색이 가능하다는 장점이 있지만
ㆍ각 노드에서 자식들에 대한 포인터들을 배열로 모두 저장하고 있다는 점에서
저장 공간의 크키가 크다는 단점도 있다.
- 검색어 자동완성, 사전에서 찾기 그리고 문자열 검사 같은 부분에서 사용할 수 있다.시간복잡도 - 제일 긴 문자열의 길이를 L 총 문자열들의 수를 M이라 할 때 시간복잡도는 아래와 같다.
ㆍ생성시 시간복잡도: O(M*L), 모든 문자열들을 넣어야 하니 M개에 대해서 트라이 자료구조에 넣는건 가장 긴 문자열 길이 만큼 걸리니 L만큼 걸려서 O(M*L)만큼 걸린다. 물론 삽입 자체만은 O(L)만큼 걸린다.
ㆍ탐색시 시간복잡도: O(L), 트리를 타고 들어가봤자 가장 긴 문자열의 길이만큼만 탐색하기 때문에 O(L)만큼 걸린다.
6. 다익스트라, 플로이드 와샬 - 최단 경로 알고리즘
다익스트라 - 다익스트라 최단 경로 알고리즘은 그래프에서 여러 개의 노드가 있을 때, 특정한 노드에서 출발하여 다른 노드로 가는 각각의 최단 경로를 구해주는 알고리즘
- '음의 간선'이 없을 때 정상적으로 동작한다.
- 다익스트라 최단 경로 알고리즘은 기본적으로 그리디 알고리즘으로 분류
ㆍ매번 '가장 비용이 적은 노드'를 선택해서 임의의 과정을 반복한다.다익스트라
알고리즘의 원리1. 출발 노드를 설정한다
2. 최단 거리 테이블을 초기화한다
3. 방문하지 않는 노드 중에서 최단 거리가 가장 짧은 노드를 선택한다.
4. 해당 노드를 거쳐 다른 노드로 가는 비용을 계산하여 최단 거리 테이블을 갱신한다.
5. 위 과정에서 3과 4번을 반복한다.
- 다익스트라 알고리즘은 최단 경로를 구하는 과정에서 '각 노드에 대한 현재까지의 최단 거리' 정보를 항상 1차원 리스트에 저장하며 리스트를 계속 갱신한다는 특징이 있다.
ㆍ이러한 1차원 리스트를 최단 거리 테이블이라고 한다.
- 다익스트라 최단 경로 알고리즘에서는 ' 방문하지 않는 노드 중에서 가장 최단 거리가 짧은 노드를 선택'하는 과정을 반복하는데, 이렇게 선택된 노드는 '최단 거리'가 완전히 선택된 노드이므로, 더 이상 알고리즘을 반복해도 최단 거리가 줄어들지 않는다.설명 - 처음에 각 노드에 대한 최단 거리를 담는 1차원 리스트를 선언한다.
- 이후에 단계마다 '방문하지 않는 노드 중에서 최단 거리가 가장 짧은 노드를 선택' 하기 위해 매 단계마다 1차원 리스트의 모든 원소를 확인(순차 탐색)한다.시간복잡도 - 시간 복잡도는 O(V^2) 이다
ㆍ여기서 V는 노드의 개수를 의미한다.
- 왜냐면 총 O(V)번에 걸쳐서 최단 거리가 가장 짧은 노드를 매번 선형 탐색해야하고, 현재 노드와 연결된 노드를 매번 일일이 확인하기 때문이다.설명 - 힙 자료구조를 이용해서 특정 노드까지의 최단 거리 정보를 처리하므로 출발 노드로부터 가장 거리가 짧은 노드를 더 빠르게 찾을 수 있다.
ㆍ이 과정에서 선형 시간이 아닌 로그 시간이 걸린다.시간복잡도 - 시간복잡도가 O(ElogV)로 휠씬 빠르다.
ㆍ여기서 V는 노드의 개수이고, E는 간선의 개수를 의미한다.플로이드 워셜
(Floyed-Warshall
Algorithm)- 다익스트라 알고리즘은 '한 지점에서 다른 특정지점까지의 최단 경로를 구하는 경우' 에 사용할 수 있는 최단 경로 알고리즘이다.
- 플로이드 워셜 알고리즘은 '모든 지점에서 다른 모든 지점까지의 최단 경로를 구해야 하는 경우'에 사용할 수 있는 알고리즘이다.
- 다익스트라 알고리즘에서는 출발 노드가 1개이므로 다른 모든 노드까지의 최단 거리를 저장하기 위해서 1차원 리스트를 이용했다.
- 반면에 플로이드 워셜 알고리즘은 다익스트라 알고리즘과는 다르게 2차원 리스트에 '최단 거리' 정보를 저장한다는 특징이 있다.
- 또한 다익스트라 알고리즘은 그리디 알고리즘인데 플로이드 워셜 알고리즘은 다이나믹 프로그래밍이라는 특징이 있다.시간복잡도 - 노드의 개수가 N개일 때 알고리즘 상으로 N번의 단계를 수행하며, 단계마다 O(N^2)의 연산을 통해 '현재 노드를 거쳐 가는' 모든 경로를 고려한다.
- 따라서 플로이드 워셜 알고리즘의 총 시간 복잡도는 O(N^3)이다.
7. 최소 신장 트리
서로소 집합 - 수학에서 서로소 집합(Disjoint Sets) 이란 공통 원소가 없는 두 집합을 의미한다.
- 예를 들어 집합 {1,2}와 집합 {3,4}는 서로소 관계이다.
- 반면에 집합 {1,2}와 집합 {2,3}은 2라는 원소가 두 집합에 공통적으로 포함되어 있기 때문에 서로소 관계가 아니다.서로소 집합 자료구조 - 서로소 집합 자료구조란 서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조라고 할 수 있다.
- 서로소 집합 자료구조는 union과 find이 2개의 연산으로 조작할 수 있다.
ㆍunion(합집합) 연산은 2개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산이다.
ㆍfind(찾기) 연산은 특정한 원소가 속한 집합이 어떤 집합인지 알려주는 연산이다.서로소 집합 자료구조
알고리즘- 서로소 집합 자료구조를 구현할 때는 트리 자료구조를 이용하여 집합을 표현하는데, 서로소 집합 정보(합집합 연산)가 주어졌을 때 트리 자료구조를 이용해서 집합을 표현하는 서로소 집합 계산 알고리즘은 다음과 같다.
ㆍ1. union(합집합) 연산을 확인하여, 서로 연결된 두 노드 A, B를 확인한다.
º 1) A와 B의 루트 노드 A', B'를 각각 찾는다.
º 2) A'를 B'의 부모 노드로 설정한다(B'가 A'를 가리키도록 한다).
ㆍ2. 모든 union(합집합) 연산을 처리할 때까지 1번 과정을 반복한다.서로소 집합 자료구조
시간 복잡도- 노드의 개수가 V개이고, 최대 V - 1개의 union연산과 M개의 find연산이 가능할 때 경로 압축 방법을 적용한 시간 복잡도는 O(V + M(1 + log(2-M/V)) 라는 것으로 알려져 있다. 서로소 집합을
활용한 사이클 판별- 서로소 집합은 무방향 그래프 내에서의 사이클을 판별할 때 사용할 수 있다는 특징이 있다
- union 연산은 그래프에서의 간선으로 표현될 수 있다
- 알고리즘
ㆍ1. 각 간선을 확인하며 두 노드의 루트 노드를 확인한다.
º 1) 루트 노드가 서로 다르다면 두 노드에 대하여 union 연산을 수행한다.
º 2) 루트 노드가 서로 같다면 사이클이 발생한 것이다
ㆍ2. 그래프에 포함되어 있는 모든 간선에 대하여 1번 과정을 반복한다.신장 트리 - 신장 트리(Spanning Tree)란 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다.
- 이때 모든 노드가 포함되어 서로 연결되면서 사이클이 존재하지 않는다는 조건을 트리의 성립 조건
- 신장 트리 중에서 최소 비용으로 만들 수 있는 신장 트리를 찾는 알고리즘을 '최소 신장 트리 알고리즘'이라 한다.크루스칼 알고리즘 - 크루스칼 알고리즘을 사용하면 가장 적은 비용으로 모든 노드를 연결할 수 있는데 크루스칼 알고리즘은 그리디 알고리즘으로 분류된다.
- 먼저 모든 간선에 대하여 정렬을 수행한 뒤에 가장 거리가 짧은 간선부터 집합에 포함시키면 된다.
- 알고리즘
ㆍ1. 간선 데이터를 비용에 따라 오름차순으로 정렬한다.
ㆍ2. 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인한다.
º 1) 사이클이 발생하지 않는 경우 최소 신장 트리에 포함시킨다.
º 2) 사이클이 발생하는 경우 최소 신장 트리에 포함시키지 않는다.
ㆍ3. 모든 간선에 대하여 2번의 과정을 반복한다.크루스칼 알고리즘
시간 복잡도- 크루스칼 알고리즘은 간선의 개수가 E개일 때, O(ElogE)의 시간 복잡도를 가진다.
- 크루스칼 알고리즘에서 시간이 가장 오래 걸리는 부분이 간선을 정렬하는 작업이며, E개의 데이터를 정렬했을 때의 시간 복잡도는 O(ElogE)이기 때문이다.
- 크루스칼 내부에서 사용되는 서로소 집합 알고리즘의 시간 복잡도는 정렬 알고리즘의 시간 복잡도보다 작으므로 무시한다.프림 알고리즘 - 최소 신장 트리를 찾는 알고리즘 중 하나
- 알고리즘
ㆍ1. 임의의 시작 정점을 선택하여 트리에 포함시킨다.
ㆍ2. 선택된 정점과 인접한 정점들 중에서 아직 트리에 포함되지 않은 정점들 중에서
가장 가중치가 작은 간선을 선택하여 트리에 포함시킨다.
ㆍ3. 트리에 포함된 정점들과 이어진 모든 간선 중에서 가장 작은 가중치를 가진 간선을 선택
ㆍ4. 위 과정을 모든 정점이 트리에 포함될 때까지 반복
- 우선순위 큐를 사용해서 구현프림 알고리즘
시간 복잡도- 시간복잡도는 보통 O(E log V)이다. ( E : 간선의 수, V : 정점의 수 )
- 우선순위 큐를 사용하면 각 단계에서 다음으로 선택될 정점을 빠르게 찾는다.
- 그래프가 밀집된 경우에는 크루스칼보다 효율적이다.ETC..
1. 캐시 메모리를 사용하면
컴퓨터 시스템의 성능이
왜 향상되는지
지역성(locality) 개념을 포함시켜
설명하시오- 지역성은 프로그램이 메모리에 접근할 때 특정 부분을 집중적으로 사용하는 경향을 나타낸다.
1. 시간적 지역성(Temporal Locality)
- 한 번 접근된 데이터는 가까운 미래에 다시 접근될 가능성이 높다는 원리입니다.
- 예를 들어, 루프 내에서 반복적으로 사용되는 변수는 시간적 지역성의 좋은 예이다.
2. 공간적 지역성(Spatial Locality)
- 메모리의 특정 주소에 접근한 후, 그 주변 주소에 있는 데이터에 접근될 가능성이 높다는 원리입니다.
- 이는 배열이나 연속적인 메모리 블록에 접근할 때 종종 발생한다.
- 캐시 메모리는 이러한 지역성 원리를 활용하여 자주 사용되거나 연속적으로 사용될 가능성이 높은 데이터를 미리 캐시에 저장합니다.
- 이로 인해 CPU는 필요한 데이터를 캐시에서 빠르게 찾을 수 있다.2. 프로세스와 쓰레드의 차이 ( 시스템 자원, 독립 vs 공유 키워드로 설명 )
정의
- 프로세스 : 독립적으로 실행되는 프로그램의 인스턴스로, 자체적인 주소 공간, 메모리, 데이터 스택 및 다른 시스템 자원을 갖는다.
- 쓰레드 : 프로세스 내부의 실행 흐름 단위로, 프로세스의 자원과 주소 공간을 공유하면서 실행된다.
자원 공유
- 프로세스 : 각 프로세스는 독립적인 메모리 공간과 시스템 자원을 가지므로, 프로세스간 자원 공유는 IPC(Inter-Process Communication) 매커니즘을 통해 이루어진다.
- 쓰레드 : 같은 프로세스 내의 쓰레드들은 코드, 데이터 및 시스템 자원을 공유한다.3. 데이터베이스에서
큰 양의 정렬된 데이터를
관리하고 있습니다.
B-tree 인덱스를 사용하면
데이터 검색 성능이
향상될 수 있습니다.
B-tree 인덱스를 사용할 때와
사용하지 않을 때의
데이터 검색 시간 복잡도를
Big O 표기법을 사용하여
비교하고 설명하시오- 여기서 n 은 데이터베이스 내의 레코드 수이다.
- B-tree 인덱스를 사용할 때의 데이터 검색 시간 복잡도는 O(log n) 이다.
- B-tree 구조는 균형 이진 트리와 유사하므로 데이터를 효율적으로 검색할 수 있다.
- 반면, B-tree 인덱스를 사용하지 않을 경우 선형 검색을 수행해야 하므로 검색 시간 복잡도는 O(n)이 된다.
- 따라서, 데이터 양이 많을수록 B-tree 인덱스를 사용하는 것이 성능 면에서 훨씬 유리하다.'정글 크래프톤 5기 회고 및 정리 > WIL' 카테고리의 다른 글
[WEEK05] 정글5기 - 탐험 준비 - Red-Black Tree (0) 2024.04.18 [WEEK04] 정글 5기 - 탐험준비 - C언어, 자료구조, 알고리즘 (0) 2024.04.12 [WEEK03] 정글 5기 - 컴퓨팅 사고로의 전환 (0) 2024.04.04 [WEEK01] 정글 5기 - 컴퓨팅 사고로의 전환 (0) 2024.03.22 [WEEK00] 정글 5기 - 정글 입성 (3/18 ~ 3/21) (1) 2024.03.21